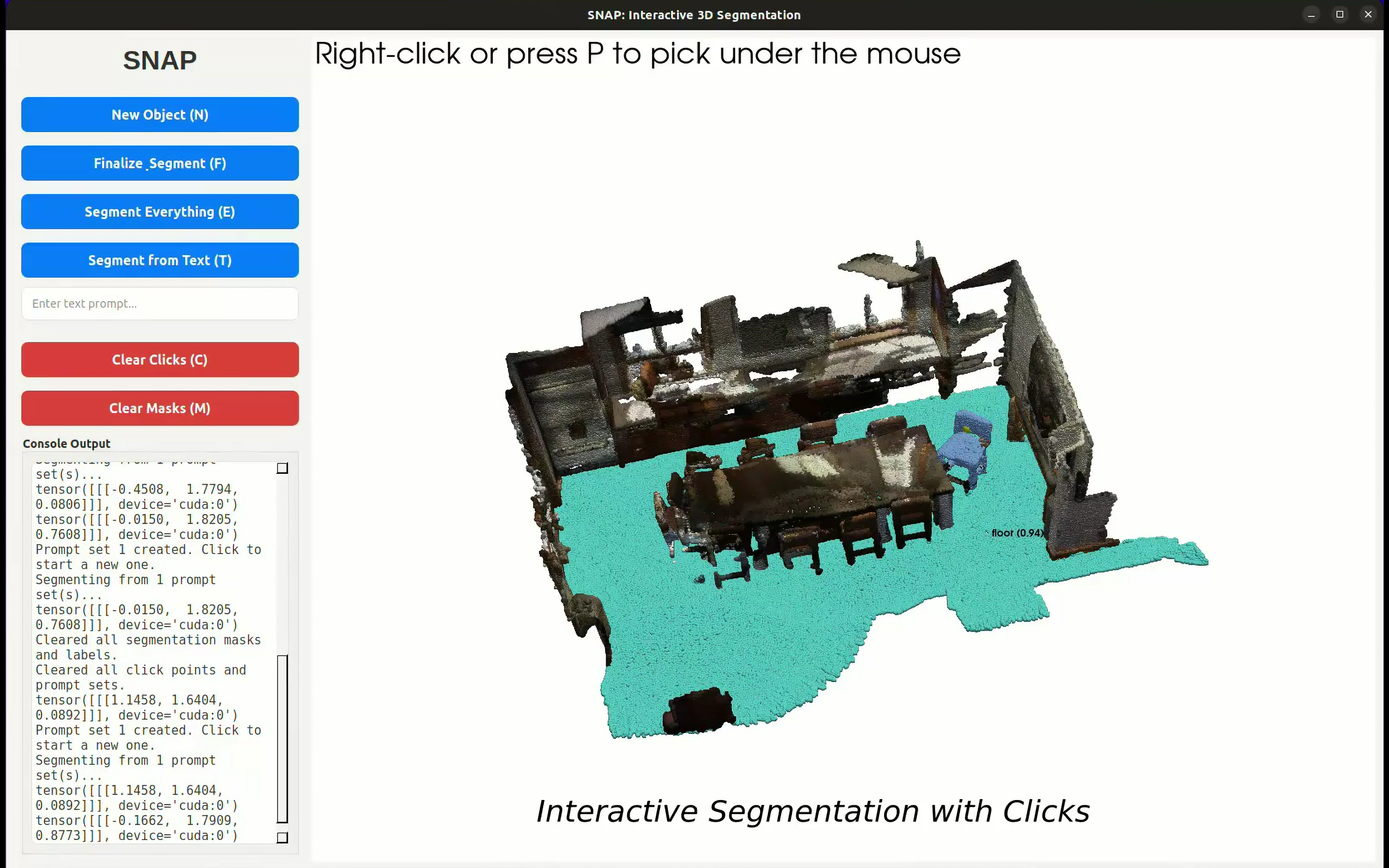
Interactive 3D point cloud segmentation enables efficient annotation of complex 3D scenes through user-guided prompts. However, current approaches are typically restricted in scope to a single domain (indoor or outdoor), and to a single form of user interaction (either spatial clicks or textual prompts). Moreover, training on multiple datasets often leads to negative transfer, resulting in domain-specific tools that lack generalizability. To address these limitations, we present SNAP (Segment aNything in Any Point cloud), a unified model for interactive 3D segmentation that supports both point-based and text-based prompts across diverse domains. Our approach achieves cross-domain generalizability by training on 7 datasets spanning indoor, outdoor, and aerial environments while employing domain-adaptive normalization to prevent negative transfer. For text-prompted segmentation, we automatically generate mask proposals without human intervention and match them against CLIP embeddings of textual queries, enabling both panoptic and open-vocabulary segmentation. Extensive experiments demonstrate that SNAP consistently delivers high-quality segmentation results. We achieve state-of-the-art performance on 8 out of 9 zero-shot benchmarks for spatial-prompted segmentation and demonstrate competitive results on all 5 text-prompted benchmarks. These results show that a unified model can match or exceed specialized domain-specific approaches, providing a practical tool for scalable 3D annotation.
@inproceedings{wang2024leveragingsamsinglesourcedomain,title={SNAP: Towards Segmenting Anything in Any Point Cloud},author={Gupta*, Aniket and Wang*, Hanhui and Saunders, Charles and RoyChowdhury, Aruni and Singh, Hanumant and Jiang, Huaizu},booktitle={The 13th International Conference on 3D Vision},year={2026}}
2025
NeurIPS’25
Struct2D: A Perception-Guided Framework for Spatial Reasoning in MLLMs
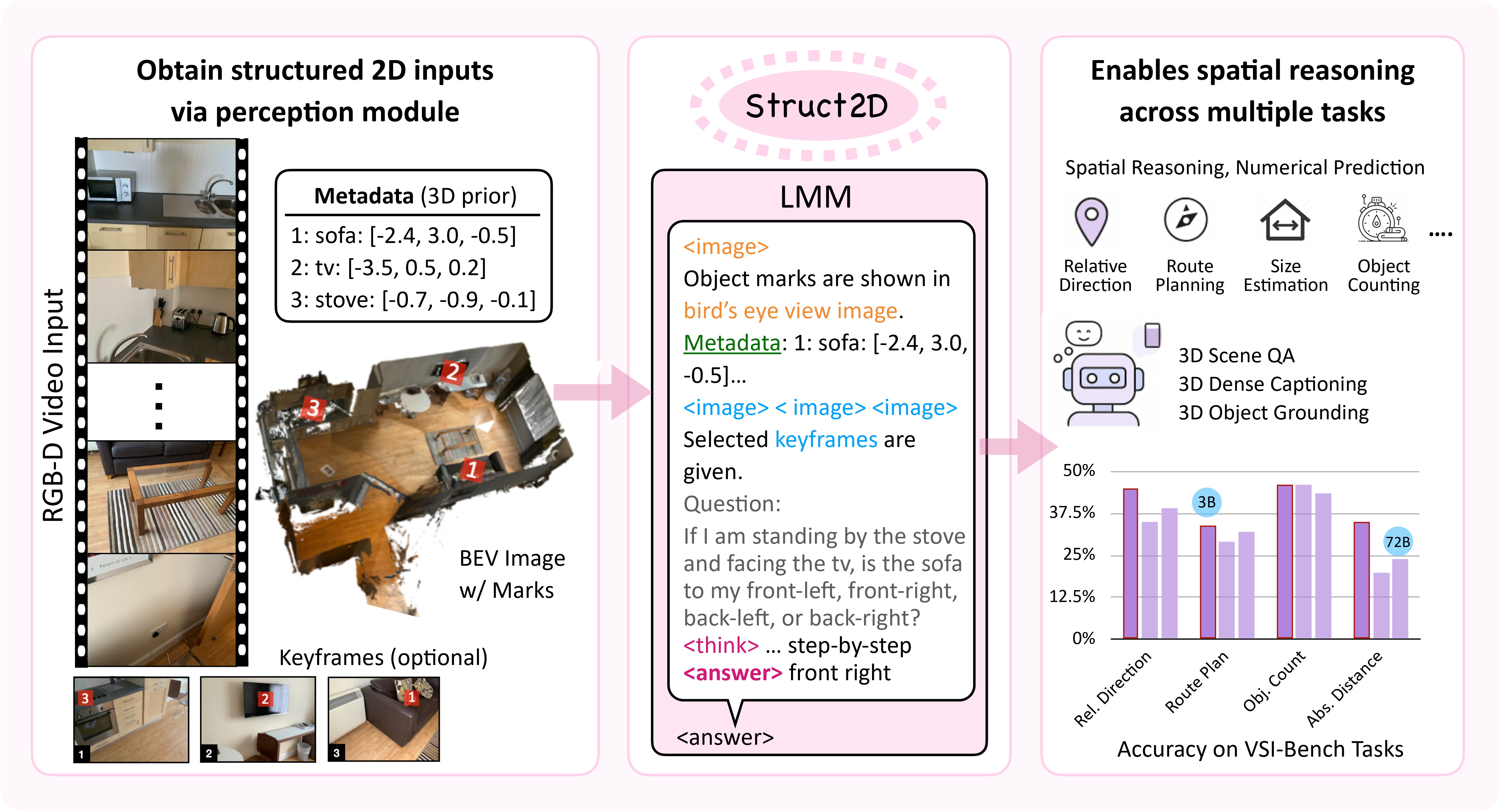
Unlocking spatial reasoning in Multimodal Large Language Models (MLLMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can MLLMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird’s-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source MLLMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source MLLM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in MLLMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
@inproceedings{zhu2025struct2dperceptionguidedframeworkspatial,title={Struct2D: A Perception-Guided Framework for Spatial Reasoning in MLLMs},author={Zhu*, Fangrui and Wang*, Hanhui and Xie, Yiming and Gu, Jing and Ding, Tianye and Yang, Jianwei and Jiang, Huaizu},year={2025},booktitle={The 39th Annual Conference on Neural Information Processing Systems}}
CVPR’25
Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing
Hanhui Wang*, Yihua Zhang*, Ruizheng Bai, Yue Zhao, Sijia Liu, and Zhengzhong Tu
In The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2025
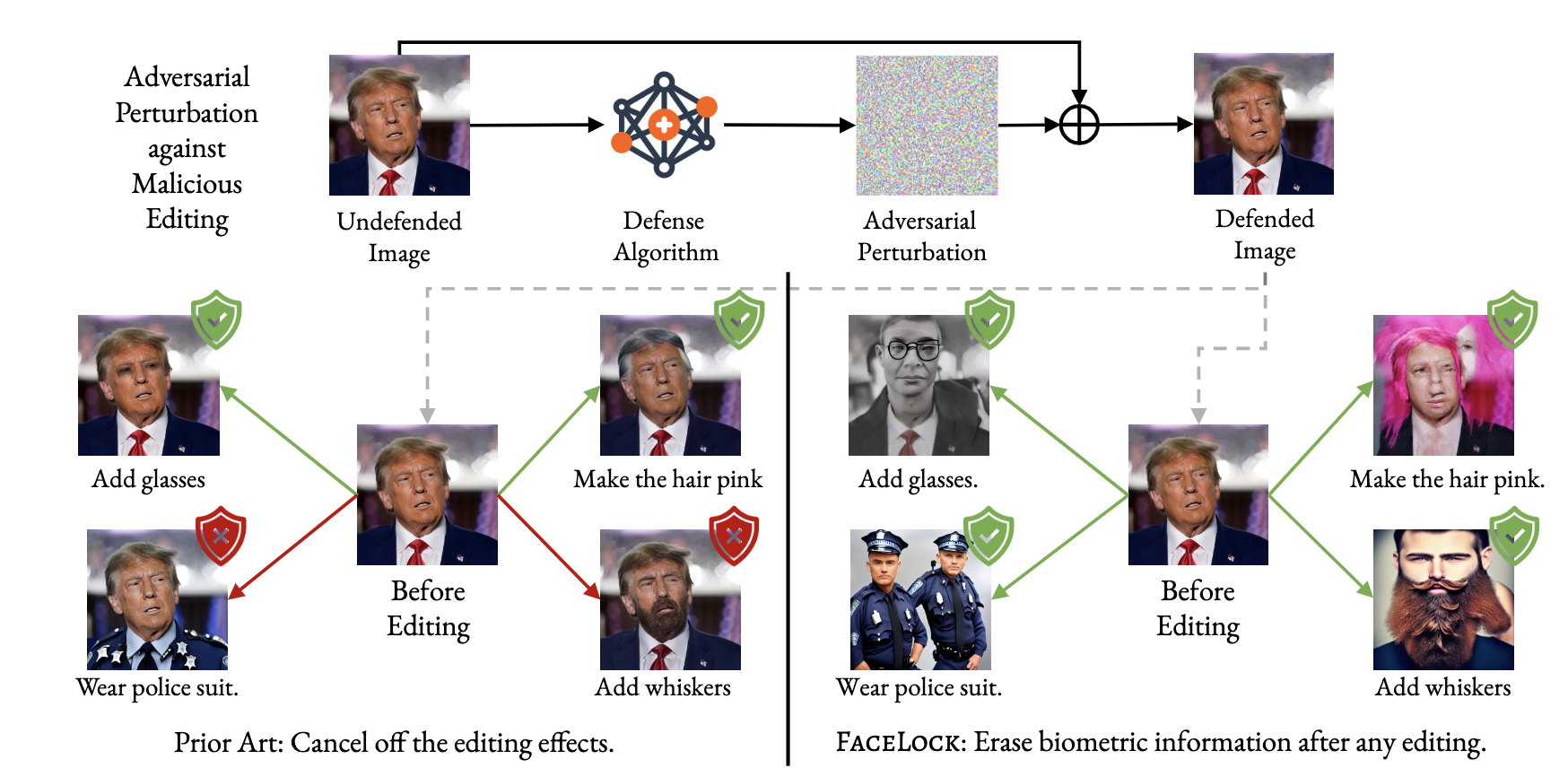
Recent advancements in diffusion models have made generative image editing more accessible than ever. While these developments allow users to generate creative edits with ease, they also raise significant ethical concerns, particularly regarding malicious edits to human portraits that threaten individuals’ privacy and identity security. Existing general-purpose image protection methods primarily focus on generating adversarial perturbations to nullify edit effects. However, these approaches often exhibit instability to protect against diverse editing requests. In this work, we introduce a novel perspective to personal human portrait protection against malicious editing. Unlike traditional methods aiming to prevent edits from taking effect, our method, FACELOCK, optimizes adversarial perturbations to ensure that original biometric information—such as facial features—is either destroyed or substantially altered post-editing, rendering the subject in the edited output biometrically unrecognizable. Our approach innovatively integrates facial recognition and visual perception factors into the perturbation optimization process, ensuring robust protection against a variety of editing attempts. Besides, we shed light on several critical issues with commonly used evaluation metrics in image editing and reveal cheating methods by which they can be easily manipulated, leading to deceptive assessments of protection. Through extensive experiments, we demonstrate that FACELOCK significantly outperforms all baselines in defense performance against a wide range of malicious edits. Moreover, our method also exhibits strong robustness against purification techniques. Comprehensive ablation studies confirm the stability and broad applicability of our method across diverse diffusion-based editing algorithms. Our work not only advances the state-of-the-art in biometric defense but also sets the foundation for more secure and privacy-preserving practices in image editing. The code is publicly available at: https://github.com/taco-group/FaceLock.
@inproceedings{wang2025edit,title={Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing},author={Wang*, Hanhui and Zhang*, Yihua and Bai, Ruizheng and Zhao, Yue and Liu, Sijia and Tu, Zhengzhong},booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2025}}
2024
arXiv’24
Leveraging SAM for Single-Source Domain Generalization in Medical Image Segmentation
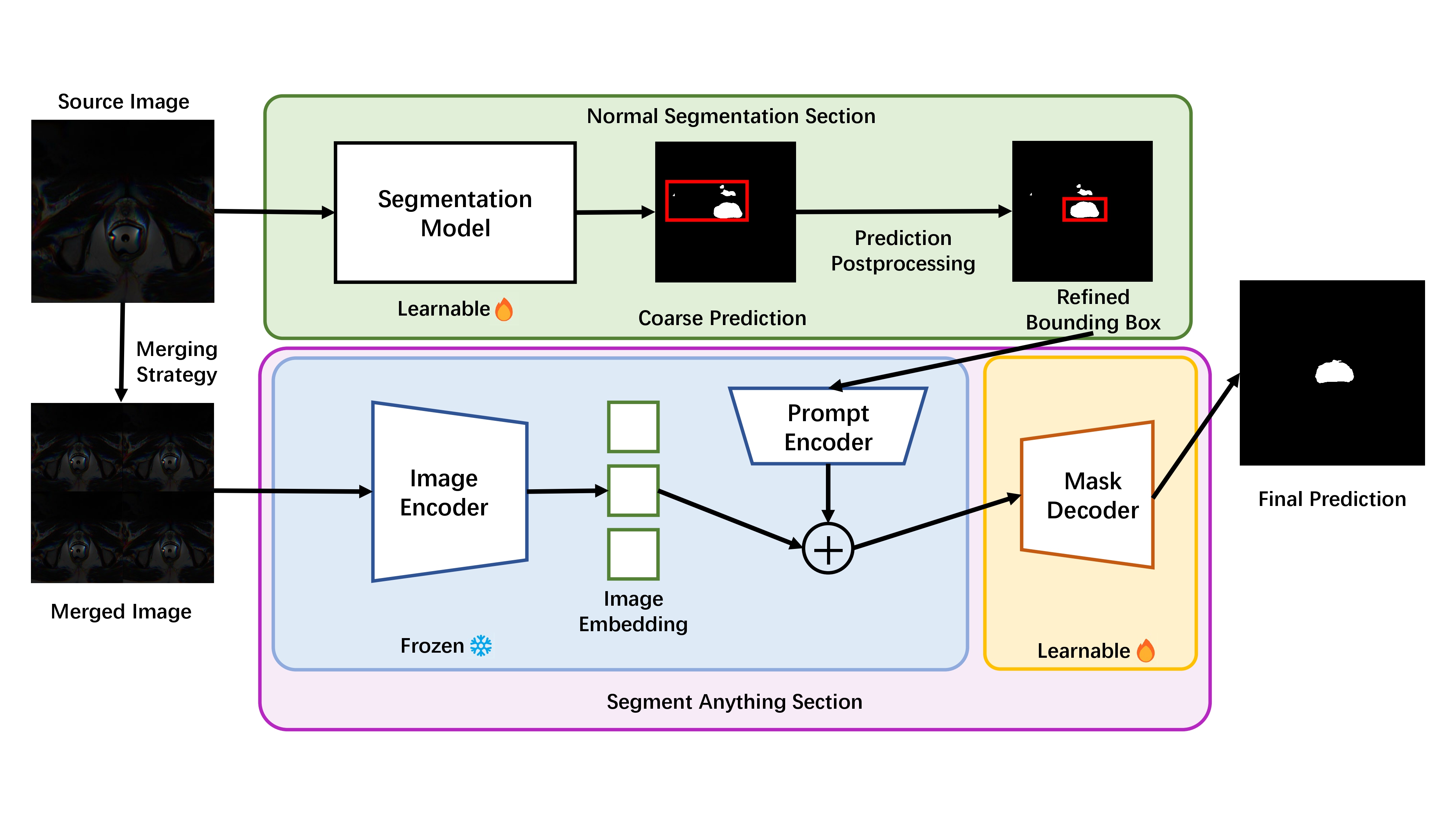
Domain Generalization (DG) aims to reduce domain shifts between domains to achieve promising performance on the unseen target domain, which has been widely practiced in medical image segmentation. Single-source domain generalization (SDG) is the most challenging setting that trains on only one source domain. Although existing methods have made considerable progress on SDG of medical image segmentation, the performances are still far from the applicable standards when faced with a relatively large domain shift. In this paper, we leverage the Segment Anything Model (SAM) to SDG to greatly improve the ability of generalization. Specifically, we introduce a parallel framework, the source images are sent into the SAM module and normal segmentation module respectively. To reduce the calculation resources, we apply a merging strategy before sending images to the SAM module. We extract the bounding boxes from the segmentation module and send the refined version as prompts to the SAM module. We evaluate our model on a classic DG dataset and achieve competitive results compared to other state-of-the-art DG methods. Furthermore, We conducted a series of ablation experiments to prove the effectiveness of the proposed method. The code is publicly available at: https://github.com/sarihust/SAMMed.
@inproceedings{wang2024leveragingsamsinglesourcedomaio,title={Leveraging SAM for Single-Source Domain Generalization in Medical Image Segmentation},author={Wang, Hanhui and Ye, Huaize and Xia, Yi and Zhang, Xueyan},booktitle={arXiv},year={2024}}